
Moneyball nel calcio: Come l'analisi dei dati crea un vantaggio competitivo sostenibile
- footballytics

- 1. März 2023
- 9 Min. Lesezeit
Aktualisiert: 17. Feb.

Sì, il nostro algoritmo avrebbe già trovato Kaoru Mitoma nella Kawasaki Frontale nel campionato J1 2020 .
L’approccio Moneyball ha cambiato il modo di valutare i giocatori. Anche nel calcio, i dati permettono di individuare valore nascosto e decisioni più efficienti. Questo articolo spiega come funziona lo scouting basato sui dati.
Cos’è l’approccio Moneyball
“Moneyball” è probabilmente la parola più utilizzata quando si parla della selezione di atleti attraverso dati statistici nello sport professionistico.
Se non si conosce bene qualcosa o non la si è provata intensamente, è difficile valutarne il pieno potenziale. In questo blog, mostriamo come utilizziamo il nostro approccio e diversi metodi e funzioni matematiche per applicare uno scouting intelligente e complementare dei dati al fine di sfruttarne appieno il potenziale.
Il data scouting è l'identificazione e non la selezione dei giocatori
Lo scopo del scouting coi dati non è quello di trovare il miglior giocatore, ma molti giocatori buoni e adatti. Vengono analizzati i profili di migliaia di giocatori per selezionare quelli adatti. Più dettagliato è il profilo di ricerca, migliori sono il filtro e il risultato.
I dati non vengono utilizzati per trovare il miglior giocatore! Vengono invece utilizzati per determinare rapidamente i 50 giocatori più adatti su 1.000, tra i quali è molto probabile che ci siano i migliori 10 (pre-scouting). In questo modo si risparmia tempo prezioso nello #scouting, perché gli scout possono concentrarsi su pochi giocatori senza doverne vagliare centinaia. L'identificazione dei migliori candidati è e rimane compito degli scout con la loro competenza ed esperienza.

Il data scouting analizza l'intero mondo del calcio con un clic
Quanto tempo impiegate per valutare approssimativamente se un giocatore corrisponde o meno al vostro profilo di ricerca? Cinque minuti o dieci? Con dieci minuti sono necessarie circa 16 ore per 100 giocatori. Un algoritmo può farlo per 100.000 giocatori in un minuto. Inoltre, con i dati è possibile trovare giocatori sorprendenti e più economici, perché c'è meno domanda al di fuori della ricerca di massa standard. Lo scouting dei dati garantisce che non ci si concentri troppo rapidamente su singoli giocatori o su quelli consigliati, ma che si cerchi nell'intero spettro. Anche dove non ci si aspetta di trovare qualcosa.
Da un punto di vista puramente statistico, a causa della quantità e della varianza, si può dire che c'è davvero un talento decennale in ogni campionato.
Il data scouting riduce la dipendenza dai consulenti/agenti
Sono ancora troppi i club che gestiscono un sistema di scouting prevalentemente reattivo. Ogni giorno gli agenti propongono loro diversi giocatori e gli scout devono impegnarsi a fondo per una rapida valutazione e, nella maggior parte dei casi, per un rifiuto. Un grande sforzo per giocatori a cui non sono nemmeno interessati.
Con questo approccio reattivo, i club si concentrano troppo presto su un numero limitato di giocatori. Per così dire, pescano solo negli stagni degli agenti/consulenti e nei loro interessi. Tuttavia, se si utilizzano i dati per identificare i giocatori adatti, è possibile ribaltare il gioco e pescare negli oceani. E poi rivolgersi ai consulenti/agenti appropriati, se necessario. Change the game.
Processo di scouting dei dati
Il processo di scouting ideale inizia con il data scouting (pre-scouting).
Vengono analizzati i profili di tutti i giocatori disponibili. Il risultato è un elenco di 30-100 giocatori candidati. Successivamente, i candidati vengono ulteriormente valutati dagli scout attraverso lo scouting video e dal vivo.

Articolo in inglese data driven scouting
Maturità nell'uso dei dati nello scouting
In base alla nostra esperienza e alle discussioni con club nazionali e internazionali, possiamo suddividere i club nei seguenti livelli di maturità nell'uso dei dati.
Utente: gli scout utilizzano i dati in strumenti forniti da fornitori professionali. Le statistiche e le metriche dei giocatori vengono confrontate in modo semplice e standardizzato. Scouting reattivo basato sulle raccomandazioni di consulenti/agenti.
Individuale: nessuna risorsa analitica propria. Alle risorse di scouting esistenti vengono assegnati compiti di analisi aggiuntivi. I dati vengono esportati dagli strumenti e analizzati in applicazioni di terze parti come Excel, Tableau, Power-Bi in base alle esigenze specifiche del club. Sviluppare KPI specifici per il club. Mix tra scouting reattivo e preventivo. Spesso non viene implementato un processo di dati coerente nello scouting.
Analista: i club dispongono di risorse analitiche dedicate che lavorano con gli scout. Applicano KPI avanzati, logiche, algoritmi e funzioni matematiche nello scouting dei dati. Lo scouting dei dati e le decisioni basate sui dati vengono adottate da tutte le parti interessate nello scouting e, se del caso, nell'analisi delle partite.
Analista Pro: dispongono di intere squadre di analisti, scienziati dei dati e matematici. Seguono un approccio scientifico e sviluppano metodi e logiche proprie per analizzare i dati. La cultura dei dati è diffusa in tutto il club.
Niente va contro l'uso di software standardizzati. Questi sono molto economici e molto validi. Ma per realizzare e sfruttare il potenziale degli analytics, è necessario investire anche nelle persone, nelle risorse e nel know-how.
Ogni club dovrebbe prendere in considerazione la possibilità di esplorarne il potenziale. Attualmente, i club cercano quasi quotidianamente analisti di dati per creare o rafforzare il loro dipartimento di analisi.
Le nuove tecnologie hanno sempre il potenziale per trasformare i sistemi, spostare i rapporti di potere e cambiare le esigenze delle posizioni dirigenziali.
L'analisi dei dati ci dice che il giocatore in questione corrisponde al profilo ricercato e ha ottenuto buoni risultati. Ma i dati sono solo una visione specifica. Come un occhio o una prospettiva in più. Come ogni altra prospettiva, non è l'unica verità. Ma sarebbe sciocco ignorare questa prospettiva per le decisioni importanti.
In ogni caso, la visione dei dati è un valore aggiunto. O conferma la nostra percezione o ci costringe a guardare più da vicino.
Tutti i club usano i dati per comparare e fare scouting. Ma solo pochi club ne sfruttano il pieno potenzialae.
Per far sì che lo scoutismo abbia successo in modo sostenibile e sistematico, è necessario che persone e gruppi diversi lavorino bene insieme e che si verifichino alcuni aspetti positivi. In altre parole:
Nelle aree delle conoscenze, delle competenze, della comunicazione, dei processi e della leadership, esiste un numero incredibile di opportunità per non solo avvicinarsi allo sfruttamento del potenziale della data analytics.
Come i Dati Creano Vantaggio Competitivo
Più di un semplice gioco di numeri
Il datascouting è molto più che confrontare numeri, modificarli in Excel, ordinarli o inserirli in un grafico x/y.
DataAnalytics è composta da calcio, informatica e matematica. Per esperienza, quest'ultima è a torto molto sottovalutata. Ma senza il know-how e le funzioni matematiche non è possibile analizzare e confrontare in modo intelligente montagne di dati.
Il nostro approccio di scouting con dati complementari
Il nostro obiettivo è trovare il maggior numero possibile di buoni giocatori
e non perdere i migliori.
Utilizziamo funzioni matematiche per aiutarci a confrontare e interpretare i dati. Ad esempio, la media, la mediana e la deviazione standard sono probabilmente le più conosciute. Altre, come la media armonica, la sigmoide, il punteggio Z e il coseno, sono probabilmente meno conosciute.
Analizziamo i dati disponibili utilizzando tre approcci diversi. In questo modo ci assicuriamo di poter trovare giocatori interessanti in diversi modi.
La NASA utilizza questo approccio anche per i viaggi nello spazio. Per massimizzare la sicurezza contro i guasti, i dispositivi più importanti non solo devono essere installati due volte, ma devono anche essere stati costruiti con due tecnologie diverse.
1) Aggiustamento del valore - Regolazione dei valori
Per confrontare i giocatori nel modo più equo possibile, regoliamo le metriche quantitative offensive e difensive con diverse unità. A seconda della metrica, per possesso, per passaggio, per tocco o anche per passaggio specifico. Il punto è mettere in relazione significativa l'input con l'output. In questo modo, i giocatori delle squadre con meno possesso vengono selezionati e possono brillare.
Più forte è la correlazione tra la metrica quantitativa e l'unità regolata, più affidabile e significativa è l'affermazione dell'analisi dei dati.
Articolo in inglese compare players fairly
2) Posizionare i profili e le metriche chiave con i filtri
Abbiamo definito oltre 20 profili di posizione dettagliati che ci permettono di analizzare con precisione i giocatori e il loro ruolo tattico. Un centrocampista difensivo, ad esempio, richiede metriche diverse rispetto a un centrocampista d'attacco, mentre un forte centrale con un'elevata progressione di palla ha requisiti completamente diversi rispetto a un classico terzino.
Grazie a questa precisa messa a punto, individuiamo i giocatori migliori e più adatti, adattati individualmente allo stile di gioco dei club. Oltre alle posizioni e ai ruoli classici, teniamo conto anche delle interpretazioni moderne, come il terzino rientrante o il false 9. Solo per i centrocampisti abbiamo definito sette profili di posizione.
Ecco un esempio di 4-2-3-1 della Premier League

3) Algoritmo di somiglianza
I punteggi di somiglianza sono stati utilizzati per la prima volta nello sport dal pioniere della sabermetrica Bill James. I suoi metodi sono stati utilizzati anche da Billy Beane nel baseball con gli Oakland Athletics. È noto grazie al libro/film Moneyball (The Art of Winning an Unfair Game, di Michael Lewis).
È un metodo matematico per determinare la somiglianza tra due vettori. In termini molto semplificati, confronta la somiglianza complessiva della distanza dei giocatori con la media di tutte le metriche rilevanti. Questo ci permette di esaminare i set di dati dei singoli giocatori per la somiglianza complessiva e di ottenere come risultato una copertura di -1 (opposta) e 1 (identica).
Possiamo quindi partire da un giocatore di riferimento e trovare giocatori simili.
Prendiamo ad esempio Lionel Messi. Possiamo usare l'algoritmo per cercare giocatori in tutti i campionati del mondo che abbiano un profilo/caratteristica il più possibile simile.
Questo non significa che i giocatori trovati siano bravi come Messi. Ma che hanno gli stessi punti di forza e di debolezza e sono molto simili nello stile e nell'espressione. Anche con questo metodo, troviamo giocatori interessanti che a volte diventano più interessanti solo ad un esame più attento... .
Come esempio pratico, prendiamo il vincitore della Champions League del Manchester City, Kevin de Bruyne. Ha valori eccezionali in varie dimensioni. Se applichiamo l'algoritmo a lui, troviamo Iliass Bel Hassani dell'RKC Waalwik in Eredivisie, con una somiglianza del 93,21%. A proposito, il suo contratto scade il 31 maggio 2023 ;-)
Profili a confronto diretto.

Bel Hassani purtroppo ha già trent'anni e l'età migliore per lo scouting. Ma le cose si fanno interessanti quando applichiamo l'algoritmo a giocatori più giovani.
Tra gli altri, troviamo Matt O'Riley (22) del Celtic Glasgow con una somiglianza dell'84,8%. Certo, in un campionato con una forza diversa, ma un giocatore giovane e sviluppabile con un profilo di forza simile a quello di Kevin De Bruyne.

Naturalmente, troviamo anche giovani giocatori della Super League, della Bundesliga, della Bundesliga austriaca e di ogni altro campionato.
Lennart Karl ha già dimostrato ottime qualità nella squadra Under 17 del Bayern Monaco,
con un Similarity Score rispetto a Ousmane #Dembélé pari all'89,45%.
In questo modo possiamo individuare con largo anticipo le stelle di domani.

Che si tratti di De Bruyne, Messi, Kimmich, Barella, Grealish, Pedri, Haaland, Neymar, Osimhen, Kim Min-jae e altri, grazie a una matematica intelligente è possibile individuare giovani giocatori di talento con profili simili a quelli delle superstar.
Le possibilità sono ampie. Si potrebbe anche individuare la squadra clone U23 del Manchester City come esempio. Anche dedicata a un campionato o a una regione.
4) Scouting dei picchi
Un altro dei nostri approcci complementari consiste nel trovare i giocatori che superano tutti in una metrica o nel contare il numero di metriche in cui si posiziona al di sopra dell'85° percentile rispetto agli altri giocatori. Il Brighton & Hove Albion, in particolare, segue questo approccio. Un esempio è Malik Tilmann (21 anni, PSV) che si colloca al di sopra dell'85° percentile in 6 metriche offensive.

Omar Marmoush dell'Eintracht Francoforte ha sei valori top assoluti nelle sue metriche a dicembre 2024.
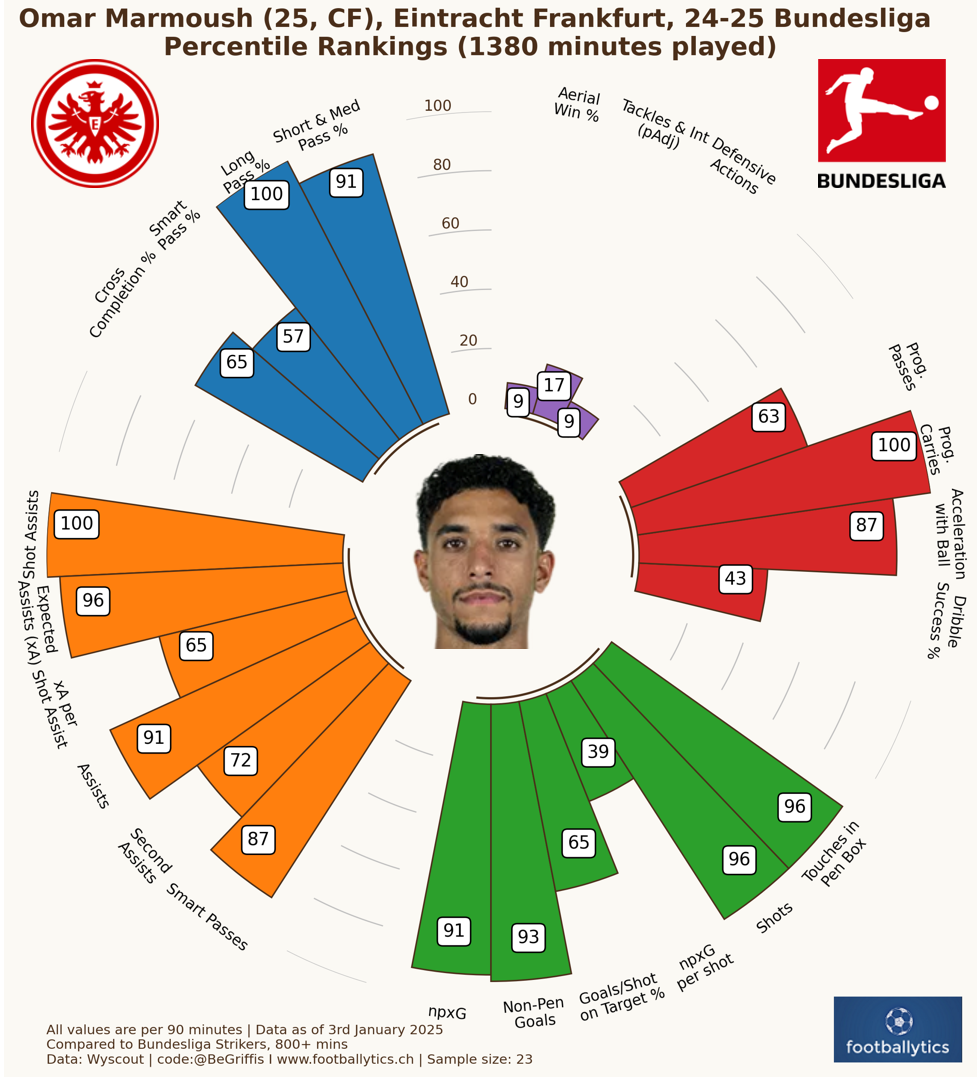
A volte è meglio non cercare di trovare il giocatore perfetto. È meglio invece trovare il giocatore con due o tre picchi eccezionali in metriche rilevanti. Perché le debolezze possono essere minimizzate dalla filosofia di gioco e dallo sviluppo del giocatore.
Il datascouting non è una scienza esatta. Non esiste un'unica via d'oro. Ma più si studia e si impara sull'argomento, più si hanno a disposizione opzioni e soluzioni complementari.
Incoraggio tutti club e agenzie a investire non solo in software, ma anche in persone e in know-how analitico. Altrimenti rimarranno un gruppo nella folla. Iniziate un percorso di apprendimento e raccogliete le vostre esperienze. È l'unico modo per cogliere il potenziale dell'uso dei dati e, se possibile, sfruttarlo.
Dati e video sono complementari.
Insieme ci aiutano ad affinare la nostra comprensione del gioco e dei giocatori.
Senza video, perdiamo informazioni. Senza dati, perdiamo informazioni.
La domanda da porsi non è: "Devo usare i dati o guardare alcune partite?", ma piuttosto.
"Quanti dati dovrei usare per questa analisi? e quanti video?"
Non possiamo fare a meno di concludere con una citazione di un matematico.
"Datemi un punto fisso e scardinerò la terra". Archimede
Lavorate con un partner, non solo con una piattaforma.
Custom Football Analytics and Data-Driven Scouting Solutions
Learn analytics – explore our free podcasts and videos.
Discover how data, tactics and AI come together in football. Each Learncast is short, practical, and packed with real insights.👉 Start your learning journey now
Podcast italiano:
footballytics – we know how to make the data talk
We support clubs, coaches, agencies and players with analysis and consulting services in the use and interpretation of data. To make better decisions in scouting, in match analysis and on the pitch.
Work with a partner, not just a platform. Here you find a description of our services
Blog von www.footballytics.ch
About Data Analytics in football. improve the game - change the ǝɯɐƃ
Share this post


